

캐시(Cache)란 데이터나 값을 필요로할때마다 불러오지 않고 중간에 복사하여 저장하는것을 말합니다

위사진은 실제로 컴퓨터에서 사용하는 캐시(Cache)로써 위로갈수록 속도는 빠르지만 비싸고, 용량이 작다는 특징을 가지고있습니다
위 피라미드 구조를 보게되면 Registers와 Main Memory 사이에는 L1, L2, L3 Cache가 존재하는데요
사실 속도가 빠르고, 용량이 크며, 값이 싼 메모리는 존재할수가 없습니다 그렇지만 비슷한 효과를 낼수있는데
바로 중간에 캐시를 두어 데이터가 만약 자주쓰이며, 동일한 결과를 돌려주는 경우
캐시에 임시로 저장하여 굳이 SSD/HDD까지 내려가지않고 바로 속도가 빠른 캐시에서 연산할수 있게되는것입니다
동일한 결과를 돌려주며, 해당 작업을 반복해야할 경우 (이미지 등)
데이터를 접근하는 시간이 오래걸리는 경우 (서버의 동일한 API)
만약 서버에 지속적으로 데이터를 얻기위해서 요청을 보내야한다면 서버는 또 데이터베이스와 커넥션을 하여 사용자가 찾는 데이터를 꺼내서 반환해줄것입니다 하지만 Cache에 미리 데이터를 복사해놓는다면 굳이 서버에 요청을 보내지않고도 사용자에게 빠르고, 효율적이게 요청을 수행할수있습니다
사용자가 많고 요청이 많아질수록 서버의 부하가 줄어들며, 유의미한 속도향상을 가져갈수있습니다
여기서 데이터가 캐시에 존재하는경우를 Cache Hit라고하며 데이터가 캐시에 존재하지않아서 서버에 요청을 해야한다면
이를 Cache Miss라고 합니다 보통 캐시는 속도가 빠른대신에 저장공간이 작기때문에 Cache Miss에 비율이 높다면
캐시된 데이터를 교체하는 것이 좋습니다

위 그래프는 Long Tail의 법칙으로써, 이는 20%의 요구가 시스템의 리소스 대부분을 사용한다는 법칙을 그래프로 표현한것입니다 이 20%에 요구를 Cache를 사용하면 성능을 비약적으로 향상시킬수있습니다
정리해보자면 Cache에 특징은 다음과같습니다
1. 속도가 빠르지만 저장공간이 작다
2. 저장공간은 용량이큰 SSD/HDD를 사용하고 자주쓰는 데이터는 캐시에 저장하여 속도를 향상시킨다
3. 저장공간이 작기떄문에 많은 데이터를 저장할수없어 Cache Miss 비율이 높으면
데이터를 다시 선정해야한다
이로써 결국 캐시는 중간에 데이터를 저장하여 좀더 빠르게 사용할수 있도록 도와주는것입니다
그렇다면 캐싱에 대해서도 알아보도록 하겠습니다

캐싱이란 단어는 말그대로 애플리케이션의 처리속도를 높혀주기 위해서 계산된 데이터나 결과값을 캐시에 저장하고 이를통해 요청을 더빠르게하는 아키텍처 패턴입니다
사실 대부분의 애플리케이션은 명령어를 반복해서 액세스하는 경우가 많은데 이 빈도수가 높고 요청이 많다면 캐싱을
고려해보는것이 좋습니다
그렇다면 웹에서는 캐시를 어떻게 사용하는지 알아보도록 하겠습니다
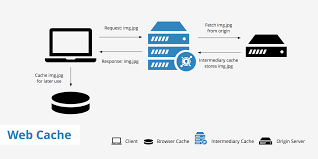
우선 웹에서의 캐시는 웹사이트에 접속할때 우리는 여러 요소들 (HTML, JS, CSS 등)을 서버로부터 다운로드 받습니다
만약 100만명의 사람이 웹사이트에 접속하면 매번 접속할때마다 100만번의 서버에요청이 가게되는데
여기서 요소들을 매번 요청해서 다운로드 하는게아니라 캐싱을 통해 서버에 요청하지않고도
컨텐츠를 바로 볼수있게됩니다
캐쉬에 종류로는
1. Brower Caches
- 브라우저 아니면 HTTP 요청을 하는 클라이언트에 의해 캐쉬
- 개인에게 한정된 캐시
- 뒤로가기나 방문한 페이지를 재방문하는 경우 효율이좋음
2. Proxy Caches
- 1번과 동일하지만 클라이언트나 서버가 아니라 네트워크상에서 동작하게됨
2. 대기시간, 트래픽, 접근 정책, 사용률등을 수행함
3. GateWay Caches
- 서버 앞에 설치되어 요청에 대한 캐시를 분배함
- 많은 클라이언트에게 제한된 수의 웹 컨텐츠를 제공함
여기서 우리는 만약 사이트에 접속한다면 어떤식으로 캐쉬가 일어나는지 보도록 하겠습니다
1. 브라우저는 서버에 HTML 파일을 요청
2. 서버는 해당파일을 찾아보고 존재한다면 브라우저에게 header의 값과 함께 Response함
3. header 담긴 캐쉬정책에 따라서 수행
캐쉬정책에는 Last-Modified, Etag, Expires 등이 있다 캐쉬정책이 따로없는경우 디폴트

- 요청한 파일의 수정시간을 비교하여 만약 동일할경우 304 Not Modified로 응답하며, 만약 수정시간이 다르다면 200을 주어 새로운 값을 응답헤더에 전송

- 서버로부터 요청한 파일의 Etag값을 비교하여 동일하면 304 Not Modified로 응답하고 Etag가 다르다면 200 과 함께 새로운 Etag의 값을 사용자에게 전송
- 만약 응답코드가 304일경우에는 변경이 이루어지지 않았으므로 캐쉬에서 컨텐츠를 가져오고 200이라면 새롭게 다운받은뒤 Etag의 값을 갱신하게 딥니다

- Expires 시간을 비교하여 유효기간이라면 서버를에 요청을 보내지않고 바로 캐시에서 페이지를 로드
하지만 기간이 만료되었을경우에는 유효성 검사작업을 실행하게됩니다
정리하자면 아래와같습니다
| 응답헤더 | 설명 | |||
| Last-Modified | 요청한 파일의 쉉시간을 Modified-Since의 값과 비교하여 캐시여부를 판단 | |||
| Etag | 요청한 파일의 Etag값을 비교하여 캐시여부를 판단 | |||
| Expire | 요청한 파일의 Expire 시간을 비교하여 캐시여부를 판단 | |||
대표적으로 웹에서는 데이터를 캐싱하기위해 데이터를 Key-Value로 저장하는 Redis라는 NoSql이 있을수 있겠습니다
해당 DB에는 데이터를 저장하여 캐시용을 사용하며, 속도가 빠르다는 장점을 가지고있습니다
'컴퓨터 > 네트워크' 카테고리의 다른 글
| SSH는 어떤식으로 작동하는 것일까? (0) | 2024.07.11 |
|---|---|
| 라우터 (Router)란 무엇일까 (0) | 2023.07.03 |
| HTTP 프로토콜 구조와 상태코드 (0) | 2023.06.11 |
| SSR 과 CSR의 장단점 및 특징에 대한 이야기 (0) | 2023.06.01 |
| HTTP의 버전으로 보는 변천사 (0) | 2023.05.29 |