

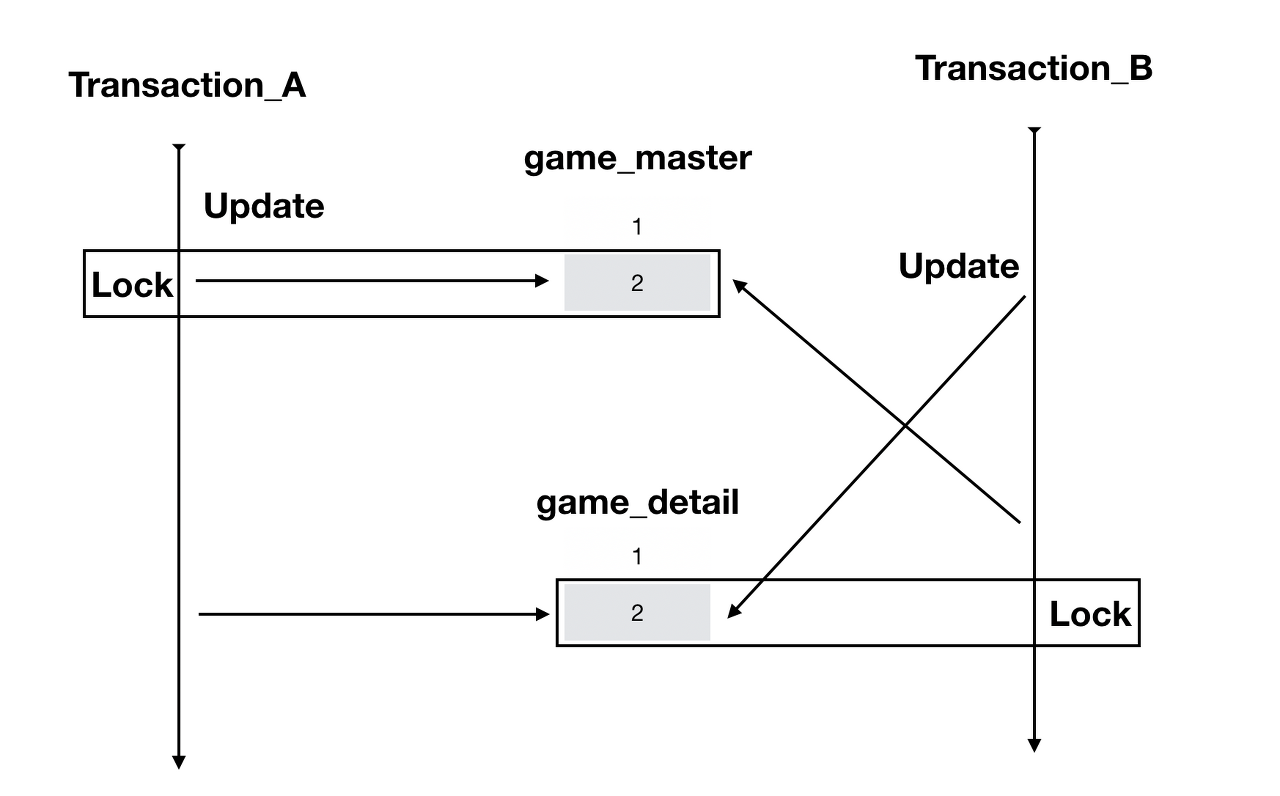
우리가 학사관리 시스템에서 수강신청 가능인원이 마지막 1명이 남았다고 가정해보겠다
2명이 동시에 정원이 1명남은 과목에 신청을 넣게되면 어떤일이 벌어지게될까?
수강신청 기능은 트랜잭션으로 묶여져있으며, 여러개의 쿼리를 거쳐서 데이터베이스의 저장이 되고 수강신청 가능인원이 1명 감소하게된다(예시)
2명이 동시에 버튼을 눌러 수강신청을 하면 동시에 트랜잭션이 시작되어 2명이 수강신청하게되면 1명이 초과되기때문에 해당 시스템에는 엄연히 문제가 있다고 볼수있다
사용자가 적은 서비스에서는 일어날확률이 적을수는 있겠지만 그렇다고 안일어난다는 보장도 하지못한다
이러한 문제를 어떻게해결할까?
나이스하게도 데이터베이스에서는 Lock이라는 개념을 지원한다
이번글을 통해서 Lock이 무엇이고 장단점이 뭐고, 특징이 무엇인지 차근차근 알아보도록 하자
Lock이 무엇일까?
다른게시물에서 트랜잭션(Transaction)에 의미에서 여러개의 쿼리를 하나의 작업단위로 묶는것을 의미했다
하지만 만약 A라는 트랜잭션에서 MONEY = 3000 이라는 데이터베이스에 저장되어있는 데이터를 접근한다고 가정했을때
A 라는 트랜잭션에서 첫번재 쿼리로 MONEY - 1500을 수행하여 MONEY = 1500이 되었다
그떄 B라는 트랜잭션이 수행되어 MONEY의 값을 읽어오게되면 1500이라는 데이터를 읽어올것이다
이떄 A라는 트랜잭션에서 서비스장애로인해 다시 RollBack처리가 됬다고 해보자 그러면 맨앞 쿼리인 MONEY - 1500이 롤백되어 다시 MONEY = 3000이 될것이다.
하지만 B라는 트랜잭션은 1500이라는 데이터를 읽었기때문에 올바른 데이터를 읽었다고 할수없다
이러한 문제를 해결해주는것이 바로 Lock으로써 트랜잭션 처리를 순서대로 처리해 독립적으로 처리할수있게 도와주는것을 의미한다
간단하게 트랜잭션의 순차성을 보장해주기 위한 방법이라고 생각하면 될것이다
이는 DBMS마다 구현방법이 조금씩 다르기때문에 자신이 사용하는 데이터베이스에서 Lock을 어떤식으로 구현하고있는지 알아보는것이 좋은선택이다
Lock의 종류
데이터베이스에서는 Lockk을 2개의종류로 나눌수있는데 첫번쨰로는 공유락(Shared Lock), 두번째로는 Exclusive Lock(베타락)이 있다
공유락은 데이터를 읽을때 사용되는 Read Lock, 베타락은 데이터를 변경할때 사용되는 Write Lock이라고 생각하면 될것이다
공유락같은경우는 여러 사용자들이 하나의 데이터에 접근하여 데이터를 읽을때 사용하는것이 공유락이며, 공유락으로 설정되어있는 데이터는 베타락을 사용할수없다
공유락같은 경우에는 데이터를 읽는 수행되는 Lock이기때문에 읽는 작업이 끝나면 해당 Lock을 반환하며, 베타락같은경우에는 트랜잭션이 완료될때까지 계속해서 유지된다 이떄 베타락은 락이 해제될떄까지 다른 트랜잭션이 해당 데이터를 접근할수 없다
이제 아래 표를 보면서 Lock에 대해서 확실히 이해해보도록 하자
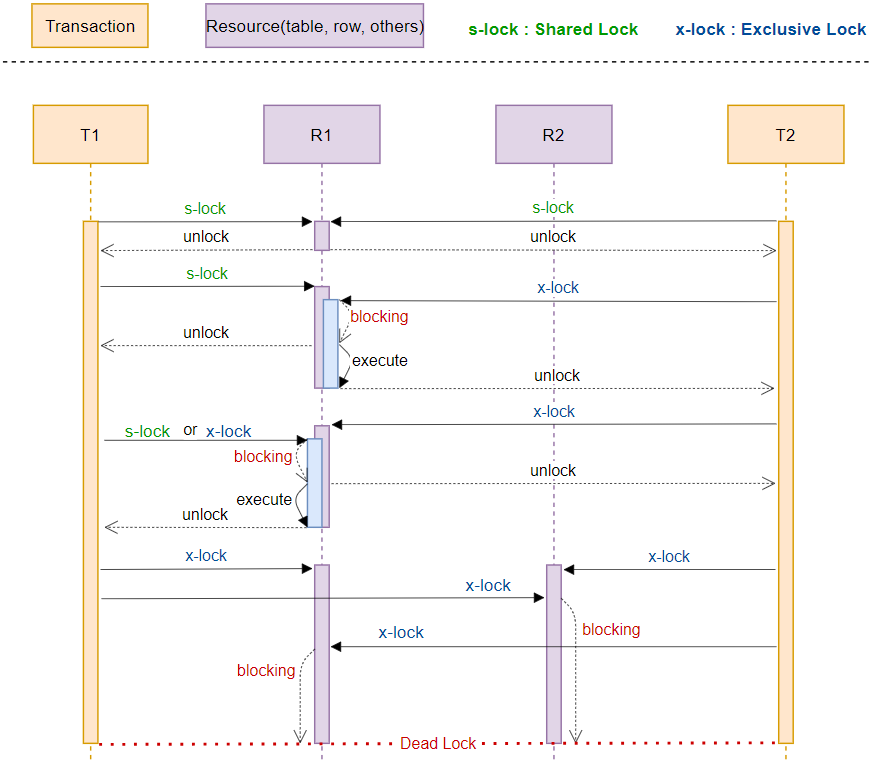
자 우선 R1이라는 곳에는 데이터가 저장되어있고 현재 시나리오는 트랜잭션1과 트랜잭션2가 R1이라는 자원을 동시에 사용할대 일어나는 일들이다
서로 공유락을 가지고있는상태에서 R1에 접근하게되면 서로 데이터를 읽는 작업만 하기때문에 동시에 접근해도 블로킹이 일어나지않는것을 확인할수있다
하지만 T1에서 공유락으로 R1을 먼저접근후 그다음 T2에서 R1에 베타락을 가진채로 접근하게되면 블라킹처리되어 막히는것을 확인할수있다
그리고 공유락이 해제되었을때 베타락이 해당 리소스에 접근하는것을 볼수있는데 이 모든것이 여러개 이상의 트랜잭션이 하나의 자원에 접근했을때 순차성을 보장해주기 위한것이라고 볼수있다
아래는 MySQL 기준으로 Lock을 설정하는 방법이다

Lock의 설정범위
Lock을 설정하는것은 전체 데이터베이스가 될수도있고, 파일이될수도있으며, 테이블, 컬럼, 행 등 다양하게 걸어줄수있다
보통 많이 사용되는것은 테이블과 행이며 나머지 다른곳에는 Lock을 잘 설정하지않는다
큰범위의 Lock을 설정하는 경우에는 보통 전체적으로 업데이트를 할경우 진행되며
그이외에는 많이사용하지 않지만 개발자의 재량이나 필요에 따라서 설정하는경우도 가끔확인된다
Lock의 장점과 단점
우선 위에서 언급한대로 트랜잭션의 순차성을 보장하여 데이터의 변경이 올바르지 않게 이루어지는것을 방지해주는 역할을한다 이는 많은 사용자가 몰리는 서비스와 하나의 자원을 공유해야하는 서비스로직이 있을경우 Lock의 설정을 필수라고 생각하면 될것이다
하지만 블로킹으로 인해 하나의 트랜잭션이 베타락(베타-베타, 베타-공유)을 가지고있으며, 다른 트랜잭션은 해당 베타락이 풀릴때까지 막힌상태로 먼저 데이터를 접근한 트랜잭션이 베타락을 unlock해야 그다음 트랜잭션이 수행될수있다
만약 트랜잭션의 길이가 길다면 불필요한 오버헤드가 될수있고, 이는 성능에 문제를 야기할수있다
사실 가장베스트는 서비스를 설계할때 같은데이터를 갱신하는 트랜잭션이 동시에 수행되지않도록 구현단계에서 방지를 하는것이 좋다
또한 Lock의 설정레벨을 큰범위로 설정하거나, 쿼리가 오랜시간 진행되지 않는등 설계적인 관점에서 신경써야 하는점이 늘어나는것또한 단점이라고 볼수있다
설계가 잘못되면 교착상태(Dead Lock)이 일어날수 있다
데드락(Dead Lock)
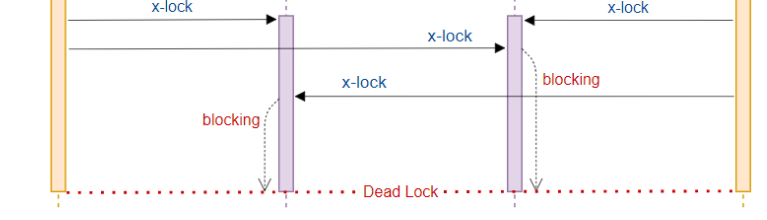
교착상태란 위에 사진에서 볼수있듯이 R1, R2에 T1과 T2가 각각점유하고있을때
중간에 T1은 R2가 필요하고 T2는 R1이 필요하여 서로 가진것을 놓치못한채로 계속해서 대기하는 현상을 말한다
내가 아이스크림 초코맛을 가지고있고 옆에친구는 멜론맛을 가지고있다고 가정을해보자
' 멜론맛 한입만 먹게해주면 내꺼 초코맛 한입줄게 '
' 초코맛 한입주면 멜론맛 한입줄게 '
이런식으로 서로가진 자원이 필요할때 블로킹되어 계속해서 원하는 데이터에 접근하지 못하게된다
이는 설계가 잘못되었을 수도있고, 데이터베이스에서는 교착상태 발생시에는 DBMS가 두개의 트랜잭션중에 하나를 에러처리하여 롤백시키며, 문제를 해결할수있도록 도와준다
이를 방지하기위해서는 접근순서를 동일하게 하는것이 중요하다
'컴퓨터 > 데이터베이스' 카테고리의 다른 글
| MySQL 프로시저(Procedure)의 의미와 실행해보기 (0) | 2023.07.08 |
|---|---|
| 데이터베이스 데이터타입과 최적화 (0) | 2023.06.16 |
| 데이터베이스 트랜잭션의 사용처와 특징 (0) | 2023.05.29 |
| 데이터베이스 빠른 검색을 위한 인덱스(INDEX) (0) | 2023.05.27 |
| 관계형 데이터베이스와 NoSQL에 대한 이야기 (0) | 2023.05.27 |